


At first glance, opening one more cafe looks simple: pick a busy street and the customers will follow. In reality, site decisions based on gut feeling carry significant risk. Leases, renovations, staff, and equipment tie up millions before the first cup is sold. Getting the location wrong is expensive.
Jakarta, like many Asian megacities, is saturated with coffee shops. Indonesia is one of the fastest-growing cafe markets in the world. Over the past decade, the number of outlets has multiplied several times, and by 2023 the sector’s revenue exceeded $2 billion. Local chains such as Kopi Janji Jiwa (1,100+ stores) and Kopi Kenangan (900+) already outnumber Starbucks by store count. The question is not whether demand exists, but where it actually forms.
Which corner will become a profitable cafe, and which will turn into a costly mistake?
Beyond Neighborhood-Level Thinking
Location decisions are often framed in broad categories: “downtown”, “residential area”, “office district”. These labels are convenient, but too coarse to explain real performance differences between individual sites.
Realytics operates at a different resolution. The model represents the world as a global hexagonal grid. Each hexagon is a 28-meter tile, designed to capture the economics of a single storefront rather than an entire district. Jakarta is one fragment of this global grid used in the model’s initial experiments. Within one cluster of neighboring hexagons, almost all showed low revenue potential. Only two stood out.
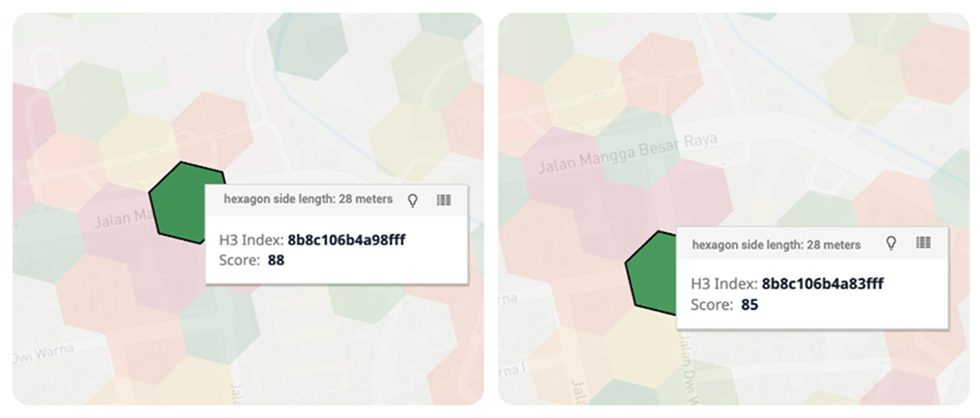
To the human eye, the streets seemed ordinary. But when we checked later, the explanation became clear: both tiles contained newly opened hospitals. The difference was not visual. It was behavioral.

The model operates on behavioral and market patterns derived from millions of market situations. These patterns combine customer behavior signals, competitive context, pricing dynamics, mobility data, demographic structure, and other parameters. Across different cases, the model learns which combinations of signals consistently translate into stronger demand. That knowledge is applied prospectively, allowing the model to evaluate new streets and corners before a business opens.
Patterns, Not Rules
The model is not hard-coded with rules such as “being near a hospital is good.” Instead, it learns patterns from observed outcomes across brands, industries, and locations, which allows it to identify both obvious and less obvious sites. Unlike many site-selection approaches that rely on mobility signals to describe exposure, this approach focuses on what actually converts into demand.

Being nearby does not imply intent: passing by a location does not necessarily lead to entering it or making a purchase. By anchoring location analysis to business outcomes Realytics can distinguish meaningful demand differences not only between districts, but between adjacent streets and even opposite sides of the same street.
The model operates on behavioral and market patterns learned from millions of cases and applies that accumulated knowledge to new locations and situations.
The model’s output is a revenue-potential score: a quantified probability that a new site will outperform its immediate surroundings. In other words, intuition is replaced by empirically learned patterns of success.

The model isn’t predicting based on assumptions. It’s learning from how real businesses perform and applying that knowledge to new locations.

A good location isn’t defined by a district. It’s defined by a point of attraction.
In Jakarta, that point was newly opened hospitals. In another city, it might be transport hubs, universities, or office clusters. By identifying these patterns early, Realytics turns site selection from guesswork into a repeatable, evidence-based process.